DropConnectを理解したかった
はじめに
ディープラーニングを行う上で、過学習(overfitting)対策は欠かせません。実際にディープラーニングを行う際、データセットを訓練データ、検証データ、テストデータ等に分割するハズです。しかし、ある場合においてはモデルが訓練データに大きく依存したものになる可能性があります。その結果として訓練データの精度が非常に高くなり、検証データ・テストデータの精度が停滞してしまいます。以下、文献[1]からの引用です。
過学習が起きる原因として、主に次の2つが挙げられます 。
・パラメータを大量に持ち、表現力が高いモデルであること
・訓練データが少ないこと出典:文献[1]
表現力はレイヤを多層化すればするほど高くなります。より性能が良いモデルを得ようとして多層化したはいいものの、学習が停滞してしまうのでは元も子もありません。過学習を抑制するための手法としては、Weight decayやDropoutなどがあります。また、Dropoutベースの正規化は、DropConnectや変分Dropoutなどがあります。
因みに、Weight decayとは、ネットワークにl2ペナルティを課すという単純な手法ですが、大抵よりよい結果が得られます。しかし、巨大なネットワークには向きません。
全結合ネットワーク(No-Drop)
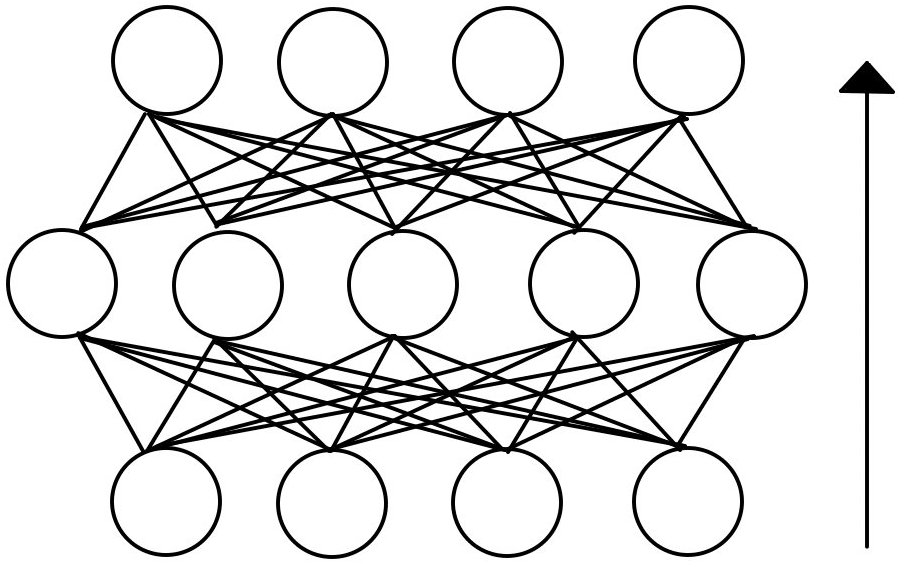
それぞれのノードは、簡単化してAffneレイヤ(Linearレイヤ)のように振舞い、何かしらの活性化関数を通るとします。(これが他であっても(例えばLSTMレイヤなど)入力と出力を考えれば同様に考えられます。ただし、全結合に限ります。)
前提として、今後扱っていく変数の概要を次に示します。
| 変数名 | 概要 | 形状 |
|---|---|---|
| 入力 | N×1 | |
| 重み | N×D | |
| Affine(Linear)の結果(行列積) | D×1 | |
| 活性化関数 |
D×1 |
上に示す基本的な全結合レイヤは次のように表せます。
それでは、この全結合のニューラルネットワークに対し、それぞれの手法を適用した場合を見ていきたいと思います。
Dropout
Dropoutは、G. Hintonらによって2012年に考案された正規化手法です。
意味としては、出力に対してDrop処理を行います。ここでいうDrop処理とは、データを確率的に削減することを指します。
グラフとして表すと下のようになります。

ここで、削減されるデータの確率(割合)を とすると、出力として残す確率は
となります。
この確率にしたがって残す部分を1、無視する部分を0としたバイナリマスクを とすると、Dropoutを導入した全結合層は次のように表されます。
ただし、 はアダマール積(Hadamard product)を表しています。アダマール積はシューア積(Schur product)や要素ごとの積(element-wise product)とも言われます。
上で述べたように、残したいものだけ残るような形になります。
シンプルなしくみでありつつ、これにて過学習に対して絶大なる効果を発揮します。
実装手法は様々なものが考案されていますので、ChainerやTensorFlowなどのソースコードを参考にするとよいでしょう。分かりやすい実装例を次に示します。(文献[1]p196参照)
import numpy as np def dropout( y, dropout_ratio = 0.5 ): mask = np.random.rand( *y.shape ) > dropout_ratio r = mask * y return r
numpyのrandom.randは、0.0から1.0の一様なランダム行列を返します。
一様という点から、dropout_ratioと比較した結果はバイナリマスクを作ることと同等になります。
また、*y.shapeは、タプル自体を渡しています。仮にy.shapeのまま渡してしまうと、y.shapeを一つの要素として、( ( x, y, z ), )のように渡されてしまいます。
DropConnect
DropConnectは、Li Wanらが2013年に発表した手法であり、Dropoutの一般化したものであるとされています(文献[2]Abstract参照)。
Dropoutと同じようにバイナリマスクを用います。
DropConnectは、上で示した(下に再掲)、Dropoutを適用した全結合レイヤを変形することで求められます。
活性化関数 によく用いられるものとしては、tanh、Relu、sigmoid等が挙げられます。
ここで、 を満たすものであれば、上の式を変形することができます。
次にバイナリマスクとして異なる形状のものを新たに用意します。
| バイナリマスク | 形状 |
|---|---|
| D×1 | |
| N×D |
すると次のように変形できます。
この式は、出力をDropするのではなく、重みをDropすることを表しています。
重みをDropするということは、なんぞ?となると思いますが、図に表すとスグ理解できるハズです。
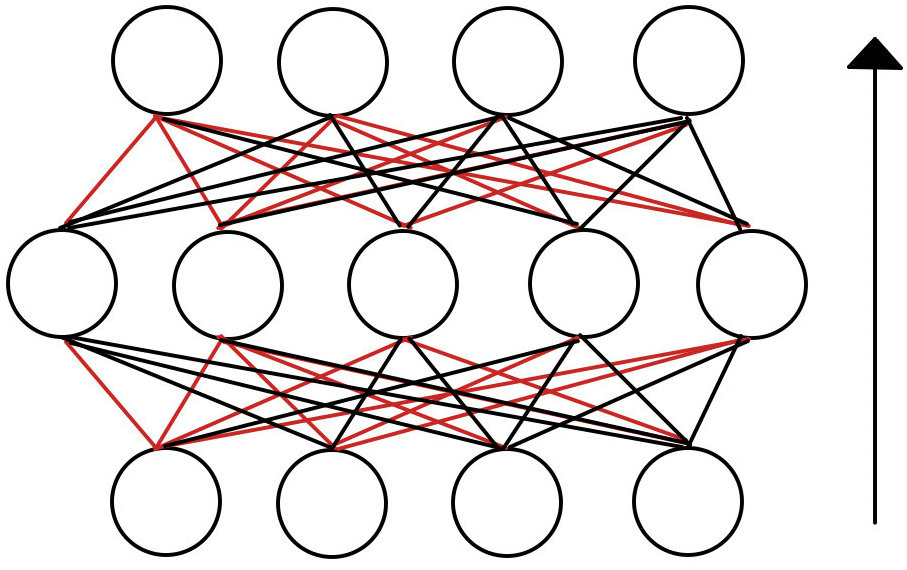
Dropしたものを赤で示しています。赤を取り除くと次のようになります。
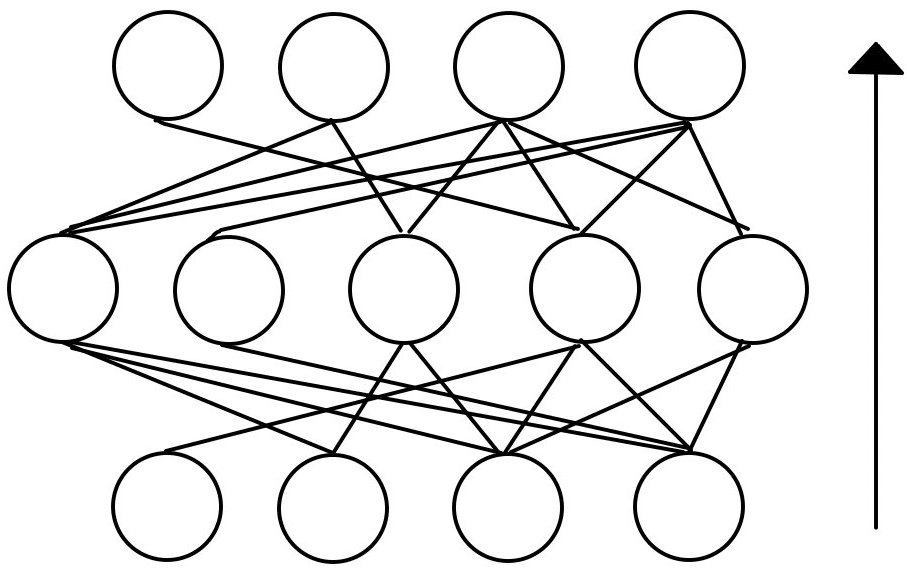
このように、出力よりもむしろ、接続を断つというのがDropConnectの手法なのです。
outが出力で、Connectが接続という観点からみても分かるでしょう。
簡単な実装では、重みと同じ形状のバイナリマスクを作り、アダマール積を行えばよいです。実装上、重みやバイアスを含むことから、文献[2]の2.2ではDropConnectをa sparsely connected layerと呼んでいます。レイヤとして一体化させたほうが扱いやすいかもしれません。
オリジナルの実装は、活性化関数を渡す前にガウス分布によるサンプリングを行います。
簡単な実装は、上で示したDropoutの例を応用すればよいです。
DropoutとDropConnectの比較
詳細な結果としての比較は、文献[2]のsection. 6をご覧ください。ここでは、簡単な比較と特徴を述べます。
ここで考えられる最も大きな違いは、バイナリマスクの表現力です。バイナリマスクを二値画像で表すと下のようになります。
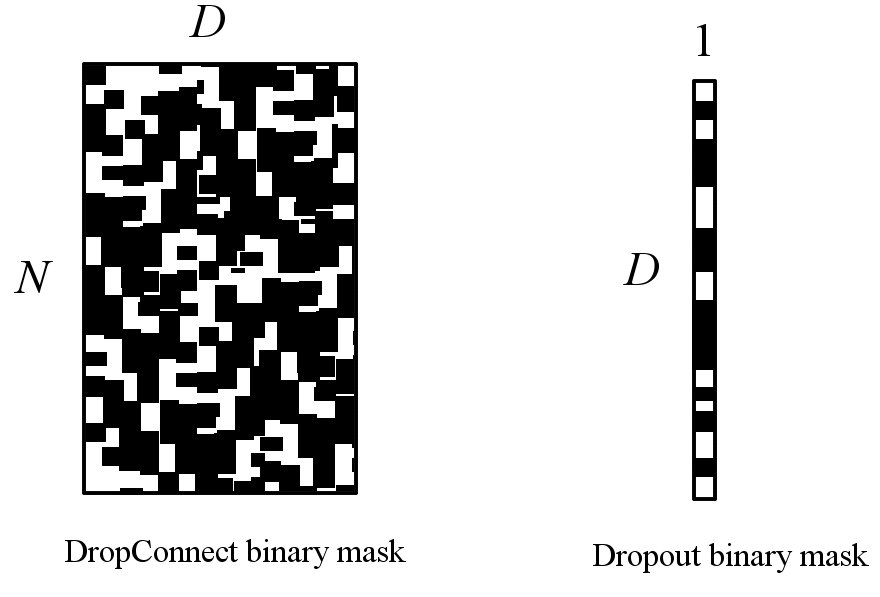
集合体恐怖症の方は大変申し訳ありません。雑いですが、元の論文を参考に作りました。
これをみると分かるように、DropConnectはより複雑なDropを行うことができます。
ニューラルネットワークのデザインにも寄りますが、大抵の場合、Dropoutよりも良い結果になります。その反面、Dropoutよりも僅かに遅いという欠点があります。また、その実装のコストが高いこともデメリットとして挙げられます。仮にChainerにてLinearレイヤ(線形全結合レイヤ)にDropConnectを導入するとします。その場合、重みに対してDrop機構を備えた線形なレイヤに入れ替えるだけで済みます。Chainerでは SimplifiedDropconnectとして用意されています。これに対して、LSTMレイヤなどに適用するとなると自前でDropConnect機構を備えたLSTMレイヤを作らなくてはいけません。逆伝播(back propagation, backward)はDropのさせ方によって簡単化することも可能なので、実装次第ですが。このように元のレイヤやコストを考慮しなくてはいけません。
以上です。
どのような手段でも構いませんので、気づいた点やご質問等ありましたら、お気軽にお寄せください。
参考文献
[1] 斎藤 康毅 (2018) 『ゼロから作るDeep Learning -Pythonで学ぶディープラーニングの理論と実装』 株式会社オライリー・ジャパン.